Download
Abstract
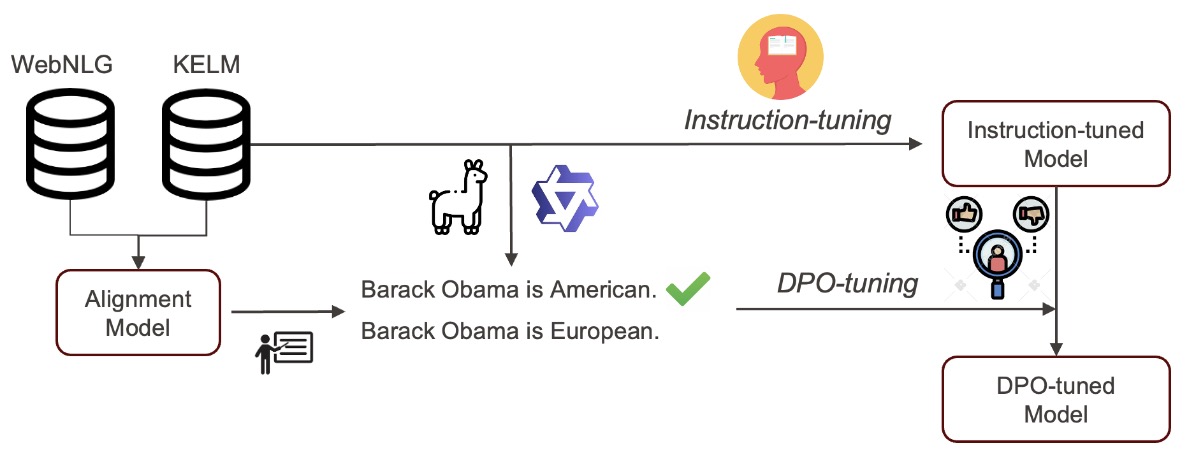
We propose MuCAL (Multilingual Contrastive Alignment Learning) to tackle the challenge of Knowledge Graphs (KG)-to-Text generation using preference learning, where reliable preference data is scarce. MuCAL is a multilingual KG/Text alignment model achieving robust cross-modal retrieval across multiple languages and difficulty levels. Building on MuCAL, we automatically create preference data by ranking candidate texts from three LLMs (Qwen2.5, DeepSeek-v3, Llama-3). We then apply Direct Preference Optimization (DPO) on these preference data, bypassing typical reward modelling steps to directly align generation outputs with graph semantics. Extensive experiments on KG-to-English Text generation show two main advantages: (1) Our KG/text similarity models provide a better signal for DPO than similar existing metrics, and (2) significantly better generalisation on out-of-domain datasets compared to standard instruction tuning. Our results highlight MuCAL’s effectiveness in supporting preference learning for KG-to-English Text generation and lay the foundation for future multilingual extensions.
Flowchart
Poster

Citation
@inproceedings{song-gardent-2025-mucal,
title = "{M}u{CAL}: Contrastive Alignment for Preference-Driven {KG}-to-Text Generation",
author = "Song, Yifei and
Gardent, Claire",
editor = "Christodoulopoulos, Christos and
Chakraborty, Tanmoy and
Rose, Carolyn and
Peng, Violet",
booktitle = "Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2025",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.emnlp-main.720/",
doi = "10.18653/v1/2025.emnlp-main.720",
pages = "14227--14270",
ISBN = "979-8-89176-332-6",
abstract = "We propose MuCAL (Multilingual Contrastive Alignment Learning) to tackle the challenge of Knowledge Graphs (KG)-to-Text generation using preference learning, where reliable preference data is scarce. MuCAL is a multilingual KG/Text alignment model achieving robust cross-modal retrieval across multiple languages and difficulty levels. Building on MuCAL, we automatically create preference data by ranking candidate texts from three LLMs (Qwen2.5, DeepSeek-v3, Llama-3). We then apply Direct Preference Optimization (DPO) on these preference data, bypassing typical reward modelling steps to directly align generation outputs with graph semantics. Extensive experiments on KG-to-English Text generation show two main advantages: (1) Our KG/text similarity models provide a better signal for DPO than similar existing metrics, and (2) significantly better generalisation on out-of-domain datasets compared to standard instruction tuning. Our results highlight MuCAL{'}s effectiveness in supporting preference learning for KG-to-English Text generation and lay the foundation for future multilingual extensions. Code and data are available at https://github.com/MeloS7/MuCAL{\_}DPO/tree/main."
}